Introduction
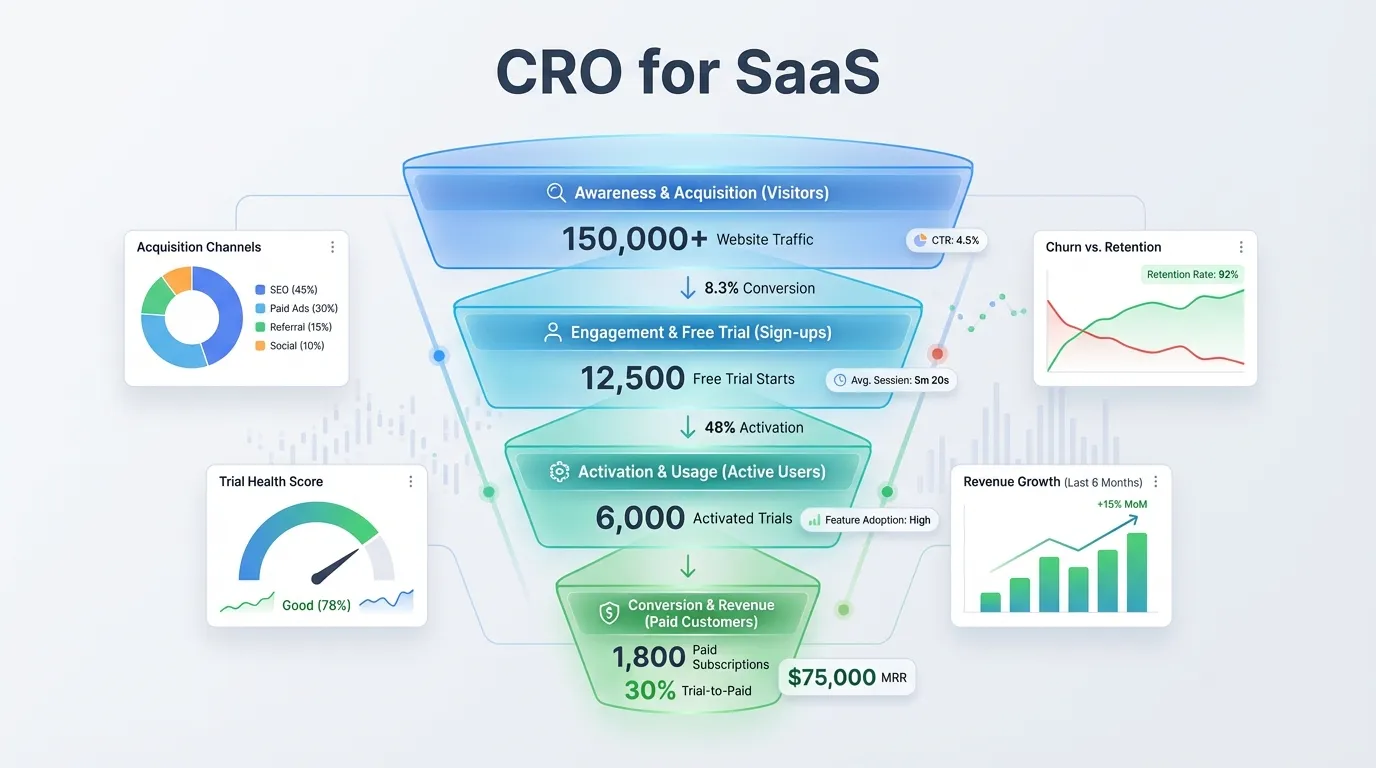
In the hyper-scale digital ecosystem of 2026, many enterprise-level businesses are unknowingly "throttling" their own organic growth. You might have 1,000,000+ pages of high-quality content, yet you notice that Googlebot is only visiting a small fraction of them every day. Important new product pages are taking weeks to appear in the index, while outdated "Zombie" pages from 2012 are still being crawled repeatedly. This is not a content problem; it is a Crawl Resource Scarcity problem. This is the definitive manual on how to optimize crawl budget for large websites.
Crawl budget is the finite number of pages Googlebot can and will crawl on your site within a specific timeframe. In 2026, with the massive computational cost of indexing AI-generated text and SGE (Search Generative Experience) references, Google has become significantly more "Selective" about where it spends its rendering energy. If your site is riddled with "Technical Noise"—such as infinite redirect loops, faceted navigation traps, or unoptimized JavaScript—you are "Paying a Tax" in the form of delayed indexing and suppressed rankings. Optimizing your crawl budget is the fastest way to "Unblock" your site's true visibility.
In this exhaustive 2,500+ word master guide, we will break down the exact procedural steps to maximize your crawl efficiency. We will explore the hierarchy of structural priority, the role of "Server Log Analysis," the impact of "Dynamic Content Control," and how to eliminate the "Crawl Latency Tax." By the end of this read, you will have a comprehensive strategy for how to optimize crawl budget for large websites and ensure your most valuable pages are always at the top of the index.
The Strategic Reality: Crawl Budget is a Limited Currency
Before we dive into the specific fixes, we must understand that Googlebot's time is "Expensive." Every millisecond your server takes to respond is a millisecond Googlebot is not spending on your next product page.
In 2026, Google evaluates "Crawl Demand" (how much it wants to crawl you) and "Crawl Rate Limit" (how much it can crawl you without crashing your server). To win, you must make every crawl "Profitable" for the bot. If the bot finds "High Value" on every page it visits, it will increase your overall budget. If it finds "Empty Parameters" and "Low Quality" content, it will withdraw its resources.
Phase 1: Structural Optimization (The "Path of Least Resistance")
If your site's hierarchy is too deep, Googlebot will get "Tired" before it reaches your money pages.
1. Achieving a "Flat" Directory Architecture
- The Strategy: Aim for a structure where every important page is no more than 3 clicks away from the homepage.
- The Fix: Use "HTML Sitemaps" (for humans) and "Deep Footers" to provide direct paths to your high-value category pages. A flat structure ensures that "PageRank" flows efficiently to your deeper nodes.
2. High-Authority Internal Linking
- The Strategy: Leverage your "Power Pages" (Homepage and top-performing blog posts) to "Boost" new content.
- The Fix: When you publish a new product, immediately link to it from your most frequently crawled pages. This signals to Google that the new page is "High Priority" and deserves an immediate slice of the crawl budget.
Phase 2: Technical Decluttering (Robots.txt and Sitemaps)
You must tell the bot exactly where to look—and where to stay away from.
1. Masterfully Managing Robots.txt
- The Tactic: Use your
robots.txtfile to block Google from crawling "Low-Value" areas like internal search result pages, admin folders, and staging environments. - The Result: By "Disallowing" these paths, you force Googlebot to spend its limited time on your "Commercial" content instead of your "Administrative" waste.
2. Dynamic XML Sitemap Optimization
- The Tactic: In 2026, static sitemaps are insufficient. You need a Dynamic Sitemap that only includes pages with a "200 OK" status.
- The Fix: Automatically remove redirected (301) or deleted (410) pages from your sitemap. Only "Primary" URLs should exist in your XML feed. This ensures zero wasted overhead during the discovery phase.
Phase 3: Server Log Analysis (The "Single Source of Truth")
The only way to know what Googlebot is really doing is to look at your "Log Files."
- The Error: You might think Googlebot is crawling your new products, but your log files show it's actually spending 50% of its time on a "Privacy Policy" PDF from 2018.
- The Fix: Perform a Log File Audit every month. Identify the "Crawl Leaks"—the specific URLs that consume high budget but provide zero organic revenue. Apply
NoindexorRobots-Disallowrules to these leaks immediately.
Phase 4: Dynamic Content Control (Faceted Navigation)
For e-commerce sites, "Faceted Navigation" (Filter sidebars) is the #1 crawl budget killer.
- The Problem: Selecting filters (e.g.,
?size=L&color=blue&price=under-50) can create trillions of "Unique URLs" that all show essentially the same content. Googlebot will get lost in this "Infinite Loop." - The Fix: Use AJax or Shadow DOM for your filter sidebars so that selecting a filter does not generate a new URL. For the URLs that must exist, use the X-Robots-Tag in the HTTP header to tell Google "Do Not Crawl" those specific parameter variations.
Phase 5: Modern Rendering (The "Latency Tax")
In 2026, "How" you serve your code determines "How Much" you get crawled.
- The Latency Tax: If your site relies heavily on client-side JavaScript (CSR) to render content, Google must "Wait" for a second rendering pass to see your text. This "Delay" burns crawl budget.
- The Solution: Use Server-Side Rendering (SSR) or Static Site Generation (SSG) for all primary content. When the page is "Pre-rendered" on the server, Googlebot can see the links and content instantly, allowing it to move to the next page 10x faster.